本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi w397090770 3年前 (2021-11-16) 463℃ 0评论1喜欢
引言 在字节跳动内部,Presto 主要支撑了 Ad-hoc 查询、BI 可视化分析、近实时查询分析等场景,日查询量接近 100 万条。 功能性方面 完全兼容 SparkSQL 语法,可以实现用户从 SparkSQL 到 Presto 的无感迁移; 性能方面 实现 Join Reorder,Runtime Filter 等优化,在 TPCDS1T 数据集上性能相对社区版本提升 80.5%; 稳定性方面 首先,实 w397090770 3年前 (2021-12-30) 679℃ 0评论1喜欢
消息队列 消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环 w397090770 9年前 (2015-08-11) 8104℃ 2评论17喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 9年前 (2015-08-26) 7189℃ 1评论42喜欢
Pandas 用户定义函数(UDF)是 Apache Spark 中用于数据科学的最重要的增强之一,它们带来了许多好处,比如使用户能够使用 Pandas API和提高性能。 但是,随着时间的推移,Pandas UDFs 已经有了一些新的发展,这导致了一些不一致性,并在用户之间造成了混乱。即将推出的 Apache Spark 3.0 完整版将为 Pandas UDF 引入一个新接口,该接口利用 w397090770 4年前 (2020-05-30) 926℃ 0评论1喜欢
一. 问答题1.请说说hadoop1的HA如何实现?2.列举出hadoop中定义的最常用的InputFormats。那个是默认的?3.TextInputFormat和KeyValueInputFormat类之间的不同之处在于哪里?4.hadoop中的InputSplit是什么?5.hadoop框架中文件拆分是如何被触发的?6.hadoop中的RecordReader的目的是什么?7.如果hadoop中没有定义定制分区,那么如何在输出 w397090770 8年前 (2016-08-26) 5688℃ 0评论5喜欢
很多人在面试中会被问到这样的题目,题目的含义是有如下的组合4=1+1+1+1、1+1+2、1+3、2+1+1、2+2。光从题目来看有两种理解: 将3 = 1 +2 和3 = 2 +1当作不同的组合。这种情况是比较简单的,直接将给定的n递归地分解成(n - 1) + 1当递归求得的结果和我们需要分解的整数n相等,则这次分解就完成了,我们可以把分解的组合输出来, w397090770 12年前 (2013-05-16) 3925℃ 0评论3喜欢
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。测试目的验证影响Alluxio加速收益的各种因素记录Alluxio w397090770 3年前 (2022-03-29) 778℃ 0评论2喜欢
时间过得真快,2021年就过去了,又到了一年总结的时候了。本文将延续之前的惯例来总结一下过去一年大数据相关的项目顺利毕业成 Apache 顶级项目。在2021年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® DataSketches™、Apache® Gobblin™、Apache® DolphinScheduler™ 以及 Apache® Pinot™;同时有两个项目进入到 Apache 孵化器, w397090770 3年前 (2022-01-03) 1349℃ 0评论5喜欢
本文是面向Spark初学者,有Spark有比较深入的理解同学可以忽略。前言很多初学者其实对Spark的编程模式还是RDD这个概念理解不到位,就会产生一些误解。比如,很多时候我们常常以为一个文件是会被完整读入到内存,然后做各种变换,这很可能是受两个概念的误导:1、RDD的定义,RDD是一个分布式的不可变数据集合; w397090770 9年前 (2016-04-20) 8435℃ 0评论33喜欢
一、定义位图法就是bitmap的缩写。所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。在STL中有一个bitset容器,其实就是位图法,引用bitset介绍:A bitset is a special container class that is designed to store bits (elements with only two possible values: 0 or 1,true or false, . w397090770 12年前 (2013-04-03) 8746℃ 0评论8喜欢
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展 w397090770 4年前 (2021-01-28) 2496℃ 0评论10喜欢
背景随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品、订单等数据的多维度检索。使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。而数据进行异构存储后,随之而来的就是数据同步的问题。现有方法及问题对于数据同步,我们目前 w397090770 5年前 (2020-01-04) 1173℃ 0评论6喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto w397090770 3年前 (2021-12-14) 719℃ 0评论1喜欢
本文作者:车好多大数据 OLAP 团队-王培,由车好多大数据 OLAP 团队相关同事投稿。Presto 简介简介Presto 最初是由 Facebook 开发的一个分布式 SQL 执行引擎, 它被设计为用来专门进行高速、实时的数据分析,以弥补 Hive 在速度和对接多种数据源上的短板。发展历史如下:2012年秋季,Facebook启动Presto项目2013年冬季,Presto开源 w397090770 4年前 (2020-12-21) 930℃ 0评论3喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章介绍了Spark的三大新特性,本文是Reynold Xin在2016年5月5日的演讲,视频可以到这里看:http://go.databricks.com/apache-spark-2.0-presented-by-databricks-co-founder-reynold-xinPPT下载地址见下面。 w397090770 8年前 (2016-05-24) 3267℃ 0评论4喜欢
HDFS 架构介绍 HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。 首先我们来介绍一下B站的HDFS离线存储平台的总体架 w397090770 3年前 (2022-04-01) 1088℃ 0评论4喜欢
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个广泛应用于统计计算和统计制图的优秀编程语言,但是其交互式使用通常局限于一台机器。为了能够使用R语言分析大规模分布式的数据,UC Berkeley给我们带来了SparkR,SparkR就是用R语言编写Spark程序,它允许数据科学家分析 w397090770 10年前 (2015-04-14) 12909℃ 0评论17喜欢
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 我们都知道,Apache Spark内置了很多操作数据的API。但是很多时候,当我们在现实中开发应用程序的时候,我们需要解决现实中遇到的问题,而这些问题可能在Spark中没有相应的API提供,这时候,我们就需要通过扩展Spark API来实现我们自己的方法。我们可 w397090770 10年前 (2015-03-30) 7184℃ 2评论15喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-03-23) 6635℃ 0评论3喜欢
4月16日在http://mirror.bit.edu.cn/apache/hive/hive-0.13.0/网址就可以下载Hive 0.13,这个版本在Hive执行速度、扩展性、SQL以及其他方面做了相当多的修改:一、执行速度 用户可以选择基于Tez的查询,基于Tez的查询可以大大提高Hive的查询速度(官网上上可以提升100倍)。下面一些技术对查询速度的提升: (1)、Broadcast Joins:和M w397090770 11年前 (2014-04-25) 8307℃ 1评论1喜欢
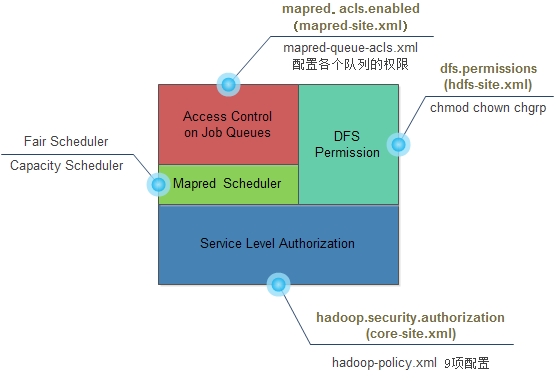
Hadoop在服务层进行了授权(Service Level Authorization)控制,这是一种机制可以保证客户和Hadoop特定的服务进行链接,比如说我们可以控制哪个用户/哪些组可以提交Mapreduce任务。所有的这些配置可以在$HADOOP_CONF_DIR/hadoop-policy.xml中进行配置。它是最基础的访问控制,优先于文件权限和mapred队列权限验证。可以看看下图[caption id="attach w397090770 11年前 (2014-03-20) 9091℃ 0评论8喜欢
理论上,在Hadoop 1.x上开发的Mapreduce程序可以在Hadoop 2.x上面运行,Hadoop2.x类库对Hadoop1.x程序的兼容性主要体现在以下几点: 二进制兼容:利用mapred API开发以及编译程序可以直接在Hadoop 2.x运行,不需要重新编译; 源码兼容:利用mapreduce API开发的程序, 需要在Hadoop 2.x上重新编译才能运行; 不兼容部分:mradmin w397090770 11年前 (2013-12-10) 6470℃ 1评论4喜欢
MySQL是一个开放源码的小型关联式数据库管理系统,开发者为瑞典MySQL AB公司。MySQL被广泛地应用在Internet上的中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。 MySQL是一种跨平台的数据库,在Ubuntu下安装Server的命令 w397090770 11年前 (2013-07-21) 3622℃ 0评论2喜欢
本书于2017-07由Packt Publishing出版,作者Giuseppe Bonaccorso,全书580页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Acquaint yourself with important elements of Machine LearningUnderstand the feature selection and feature engineering processAssess performance and error trade-offs for Linear RegressionBuild a data model zz~~ 7年前 (2017-08-27) 4626℃ 0评论14喜欢
在使用Maven打包工程运行的时候,有时会出现以下的异常:[code lang="bash"]-bash-4.1# java -cp iteblog-1.0-SNAPSHOT.jar com.iteblog.ClientException in thread "main" java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at sun.security.util.SignatureFileVerifier.processImpl(SignatureFileVerifier.java:287) at sun.security.util.SignatureFileVerifier.process(Signatu w397090770 9年前 (2016-01-20) 13248℃ 0评论9喜欢
我们在前面的 《Docker 入门教程:快速开始 》文章了解到镜像和容器的概念。本文将了解一下 Docker 的镜像分层(Layer)的概念,在 Docker 的官方文档对 Layer 的定义如下(参见这里):In an image, a layer is modification to the image, represented by an instruction in the Dockerfile. Layers are applied in sequence to the base image to create the final image. When an image is up w397090770 5年前 (2020-02-05) 1912℃ 0评论6喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 5年前 (2019-06-06) 3258℃ 0评论8喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Velox 利用了大量的运行时优化,例如过滤器和连接的重新排序(conjunct reordering)、数组和基于哈希的聚合和连接的 key 标准化、动态过滤器下推(dynamic filter pushdown)和自适应列预取(adaptive column prefetching)。考虑到从传入的数据批次中提取的 w397090770 2年前 (2022-09-05) 2147℃ 0评论3喜欢
快速管理和访问 PB 级数据的能力对于整个数据生态系统的可伸缩增长是至关重要的。尽管如此,这种对规模和速度的综合需求并不总是自然地适合现有的批处理和流系统架构。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHudi 于 2016 年以“Hoodie”为代号开发,旨在解决 Uber 大数据生态系统 w397090770 6年前 (2019-04-20) 933℃ 0评论1喜欢



















![[电子书]Machine Learning Algorithms PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_Algorithms_iteblog.png)